卷积神经网络

卷积
卷积层是卷积神经网络(Convolutional Neural Network)中的基本操作。其使用一个卷积核通过对输入层进行卷积操作,从而可以提取到图像中的高层信息。
假设输入图像是下图中的一个$6*6$的矩阵,其中每个格代表了图像点的像素值。

设置其卷积核(kernel)为$3*3$的矩阵,卷积核中的参数不同,可导致其卷积得到的结果不同:

同时,假定卷积操作每做一次卷积,卷积核移动一个像素位置,即卷积的步长(stride)为1。第一次卷积操作从图像$(0,0)$像素开始,由卷积核中的参数与对应位置图像像素逐位相乘后累加作为一次卷积结果。

对于卷积核1(filter1),其对于$(0,0)$位置进行卷积操作:
当步长为$1$时,卷积核按照补偿大小在输入图像从左到右从上到下依次将卷积操作进行下去,最终输出一个$44$大小的*卷积特征,同时这卷积特征将作为下一层操作的输入。

与之类似,若三维情形下的卷积层$l$的输入张量为$x^{l}\in R^{H^{l}\times W^{l} \times D^{l}}$,该层的卷积核为$f^{l}\in R^{H^{l}\times W^{l} \times D^{l}}$。三维输入时,卷积操作实际上只是将二维卷积扩展到了相应位置的所有通道上,最终将一次卷积处理的所有$HWD^{l}$个元素求和作为该位置的卷积结果。
若进一步,类似$f^{l}$这样的卷积核有$D$个,则在同一个位置可得到$1 \times 1 \times 1 \times D$维度的卷积输出,而$D$即为第$l+1$层特征$x^{l+1}$的通道数$D^{l+1}$。对于三维图像,形式化的卷积操作为:
其中$(i^{l+1},j^{l+1})$为卷积结果的位置坐标,在卷积层中,$f$可视作学习到的网络中的权重(weight),可以发现该项权重对不同位置的所有输入都是相同的,也就是一个卷积核时作用于不同的区域的,这也就是卷积神经网络中的权值共享特性,当然除此之外,也可以为卷积操作设定其神经元中的偏置项,当然也可将其设置为0。
零填充:
可见,对于上面介绍的卷积操作,对于一张输入图像,进行不断的卷积操作,得到的输出特征尺寸将在不断减小,有时这样是不可取的,因为最终的输出逐渐减小后,所学到的图像特征也所剩无几了。所以这里有个保证图像输出不再减小的方法,称为零填充(Zero padding)。

如上图所示,即是在卷积操作中设置$padding=1$,也就是在边缘像素周围再以1个0填充。对于本来的输入为$6 \times6$大小的图像,以卷积核为$3 \times 3$,步长为$1$进行卷积,会得到$4 \times 4$大小的输出图像。但当加上零填充之后,输入图像也就可看作是$8 \times 8$大小,进行同样的卷积操作,输出却得到了$6 \times 6$大小的图像,和输入保持不变,这样也就能增加网络中的卷积操作,学到更为高层的特征。
所以在卷积操作中有三个重要的超参数(Hyper parameters):
- 卷积核大小(filter size): $(f \times f)$
- 卷积步长(filter stride):$s$
- 零填充(padding): $p$
对于输入图像大小为$n \times n$,对于输出尺寸可以得到如下的一般公式:
当然,合适的超参数设置会对模型带来意想不到的效果提升。在pytorch中,对于二维图像的卷积操作,使用nn.Conv2d表示。
池化
在卷积神经网络中,池化层往往在卷积层的后面,通过池化来降低卷积层输出的特征向量,同时改善结果,防止过拟合。
池化通常用的两种方法为:最大值池化(Max-Pooling)和平均值池化(Average-Pooling)。
- 最大值池化:
- 平均值池化:
对于卷积后得到的图像特征,Max-Pooling可形象表示为:

这里池化的核大小选择为$(2 \times 2)$,也就是对于第一个块中,选择最大值7得到输出值。当然,如果是平均值池化,也就是取四个数的平均值作为其池化后的值。
可以发现,池化操作后的结果相比其输入减小了,其实际上是一种降采样(down-sampling),池化层的引入是按照人的视觉系统对视觉输入对象进行降采样和抽象,其主要作用主要有以下三项:
- 特征不变性:池化操作使模型更关注是否存在某些特征而不是特征具体的位置。可看作是一种很强的先验,使特征学习包含某种程度自由度,能容忍一些特征微小的位移。
- 特征降维:由于池化操作的降采样作用,汇合结果中的一个元素对应于原输入数据的一个子区域,因此池化相当于在空间范围内做了维度约减,从而使模型可以抽取更广范围的特征。同时减小了下一层输入大小,进而减小计算量和参数个数。
- 在一定程度上防止过拟合,方便优化。
LeNet-5

LeNet-5可以说是最早的卷积神经网络结构了,它主要用于手写数字识别的任务上,其发表于1998年的论文
结构:LeNet-5不包括输入层一共有7个层,每一层都包含了可以训练的参数,输入为一张$32 \times 32$的图像。
- C1卷积层
这一层的输入就是原始的图像,输入层接受图片的输入大小为$32 \times32 \times1$。卷积层的核(过滤器)尺寸为$5\times5$,深度为$6$,不使用$0$进行填充,步长为$1$。通过计算公式可以求出输出的尺寸为$28\times28\times6$,卷积层的深度决定了输出尺寸的深度。卷积层总共的参数有$5516+6 =156$个参数,加的$6$为卷积后的偏置项参数。本层所拥有的节点有$28286=4704$个节点, 而本层的每一个节点都是经过一个$5\times5$的卷积和一个偏置项计算所得到的,$55+1=26$,所以本层卷积层一共有$4704*26 = 122304$个连接。
- S2池化层
本层的输入是C1的输出,它接收一个$28\times28\times6$大小的矩阵。在卷积神经网络中,常有的池化方法为最大池化和平均池化,由于使用的核为$2\times2$,步长也为$2$,意味着每四个相邻元素经过S2之后会得到一个输出,所以输出矩阵大小变为$14\times14\times6$大小。
- C3卷积层
本层卷积操作,采用的卷积核仍为$5\times5$,使用$16$个卷积核,也就是深度为$16$,同样不使用零填充,步长为$1$,所以得到输出大小为$10\times10\times16$。
- S4池化层
本层采用同S2相同的池化操作,使输出值再缩小一半量级,变为$5\times5\times16$。
- C5卷积层
C5层由$120$个卷积核组成,一个卷积与S4中每一个feature map($5516$)相连,所以每一个C5的卷积核都会输出一个$11$的矩阵,所以在S4与C5之间是可看作属于全连接。C5是一个卷积层而不是一个全连接层,如果这个LeNet5的输入变的更大了而其它的保持不变,那么这个输出将要大于$11$。
- F6全连接层
F6层包含了$84$个结点,计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数,来产生一个输出,也就是之前的输入为$120$个神经元,现在通过一层全连接,其中含$84$个神经元,来将输出降维。
- 输出层
输出层是由欧式径向基函数(RBF)组成。每一个输出对应一个RBF函数,每一个RBF函数都有$84$维的输入向量.。每一个RBF函数都会有一个输出,最后输出层会输出一个10维的向量。,以映射到10个数字分别的预测的准确度。
MNIST数据集
MNIST数据集是入门的第一个数据集,其数据都为$28\times28$大小的单通道图像,它含有$60000$张训练图片,和$10000$张验证图片。其形式非常简单,图像如下图

用LeNet-5对MNIST数据集进行训练,可以取得92%左右的效果,已比传统机器学习方法实现的效果更好。
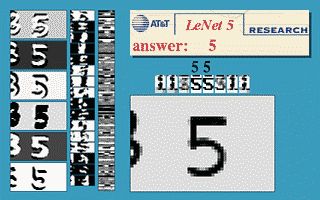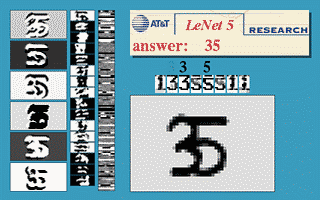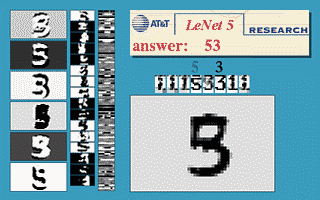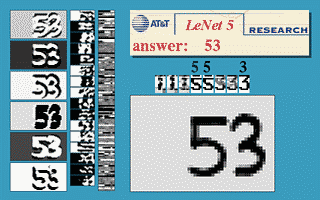
通过pytorch实现的LeNet结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(6, 16, 5)
# self.conv3 = nn.Conv2d(16, 120, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
out = F.relu(self.conv1(x)) # 28*28*6
out = F.max_pool2d(out, 2) # 14*14*6
out = F.relu(self.conv2(out)) # 10 *10 *16
out = F.max_pool2d(out, 2) # 5*5*16
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
AlexNet
在LeNet-5之后,卷积神经网络由于硬件,数据等元素的局限,训练较为困难,所以发展一直都是不温不火,直到AlexNet在2012年ImageNet竞赛中以超越第二名10.9个百分点的优异成绩一举夺冠,从而打响了卷积神经网络、乃至深度学习在计算机视觉领域中研究热潮的“第一枪”。
结构:

在AlexNet的网络结构中,共含五层卷积层和三层全连接层。AlexNet的上下两支是为了方便同时使用两片GPU进行训练,不过在第三层卷积和全连接层处上下两支信息可交互。由于两支网络完全一致,只需对其中一支进行分析。
- 卷积层C1:输入图像为$3\times224\times224$大小,实际是$3\times227\times227$大小,卷积核为$1111$,不使用零填充,步长为$4$,总共使用$96$个卷积核,由公式可得$\lfloor\frac{227-11}{4}+1\rfloor=55$,即由卷积得到$96\times55\times55$大小的特征图。采用$33$尺度,步长为$2$去池化,则池化后的图像尺寸为$27$,所以像素规模为$96\times27\times27$,由于采用两个GPU,则分为两组,每组大小为$48\times27\times27$。
- 卷积层C2: 对于上一层的输出,采用$256$个$3*3$大小的卷积核,使用$1$个padding,步长为$1$,对其进行卷积得到$256\times26\times26$的特征图,对其同样采用最大池化,上下两层分别得到$128\times13\times13$大小的输出特征图。
- 卷积层C3:此层采用$384$个$3*3$大小的卷积核,同样使用$1$个零填充,上下两层分别得到$192\times13\times13$大小的输出图。
- 卷积层C4: 同上一层,此层采用$384$个$3*3$大小的卷积核,同样使用$1$个零填充,上下两层分别得到$192 \times13\times13$大小的输出图。
- 卷积层C5:此层采用$256$个$3*3$大小的卷积核,同样使用$1$个零填充,上下两层分别得到$128\times12\times12 $大小的输出图。再采用最大池化,降维到$128\times 6 \times 6$大小。
- 全连接层 : 之后共采用了三层全连接结构,对于其中一个GPU, 特征大小逐渐从$12866$到$2048$,再从$2048$到$2048$,最后将两个GPU合并,也就是将特征从$4096$映射到$1000$,也就是ImageNet中类别的数量。
贡献:
- AlexNet 首次将卷积神经网络应用于计算机视觉领域的海量图像数据集ImageNet, 揭示了卷积神经网络拥有强大的学习能力和表达能力。另一方面海量的数据也能防止神经网络过拟合。自此引发深度学习井喷式增长。
- 利用GPU实现网络训练,之前由于计算资源的发展受限,阻碍了神经网络的研究进程。如今,利用GPU已大大减少了大型网络模型开发的成本和时间。
- 一些训练技巧为之后研究打下了基础。ReLU激活函数,局部响应规范化(LRN)操作(如今已不常用),随机失活(Dropout: 随机再网络中去除一些连接),这些训练技巧不仅保证了模型的性能,也为之后深度卷积神经网络构建提供了范本。
代码实现:
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
LRN(local_size=5, alpha=0.0001, beta=0.75),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2, groups=2),
nn.ReLU(inplace=True),
LRN(local_size=5, alpha=0.0001, beta=0.75),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
VGG
VGG网络有类似Alex的形式,但它在一些地方也有不同。
- VGG-Net中普遍使用了小卷积核,AlexNet多采用的大于5的卷积核,而VGG的卷积核多为$3*3$
- 网络卷积层的通道数从$3\to64\to128\to256\to512$。通道数逐渐变得很大,学到的特征多。
- VGG中的卷积很多都保持了输入大小,也就是卷积后大小保持不变,为的是在增加网络深度时确保各层输入大小随深度增加而不极具减小。
结构


ResNets
理论和实验表明,神经网络的深度和宽度是表征网络复杂度的两个核心因素,不过深度相比宽度在增加网络复杂性上更加有效,然而随着深度的增加,训练会变得愈加困难。这主要是因为在基于随机梯度下降的网络训练过程中,误差的多层反向传播会导致梯度弥散或梯度爆炸。可能随着网络的训练,误差并未减少而却增加。残差网络(ResNets)便很好地解决了这一问题。
残差块

残差网络主要受高速网络的影响,假设某卷积神经网络有$L$层,其中第$i$层的输入为$x^{i}$,参数为$w^{i}$,该层的输出为$y^{i}=x^{i+1}$,忽略偏置,则之间关系表示为:
其中,$F$为非线性激活函数,而对于高速网络来言,$y$的计算定义如下:
其中$T,C$是两个非线性变换,分别称作“变换门”和“携带门”。变换门负责控制变换的强度,携带门则控制原输入信号的保留强度,由于增加了保留原输入数据的可能性,所以这种网络会更加灵活。而残差网络可以看作其的特殊情况:本来优化目标为:
简单变形为
也就是说,网络所要学习的就是残差项$y-x$。残差块有两个学习分支,其一是左侧的残差函数,其二为右侧对输入的恒等映射。这两个分支经过简单的整合,再经过一个非线性变换ReLU,从而形成网络的残差块。由多个残差块堆积而成了残差网络。
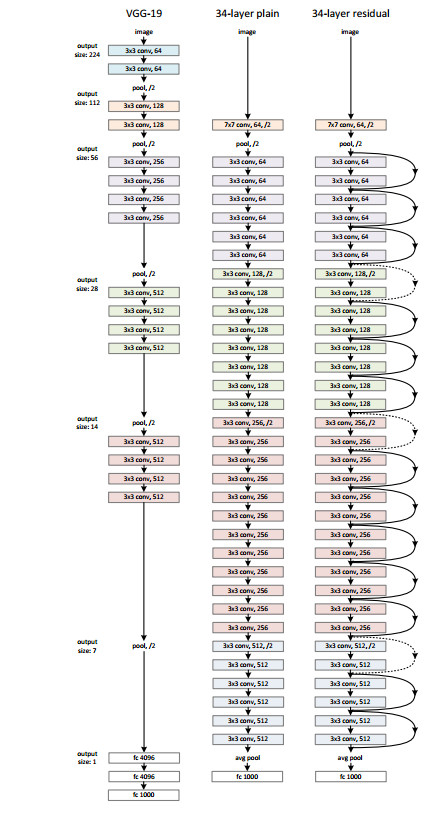
- 利用pytorch构建残差块
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual # 加上残差项
out = self.relu(out)
return out
GoogLeNet
由于增加网络的深度和宽度会导致训练难以进行下去,Inception主要思路是用密集成分来近似最优的局部稀疏结构去加深网络的同时,增宽网络结构。
Inception模块
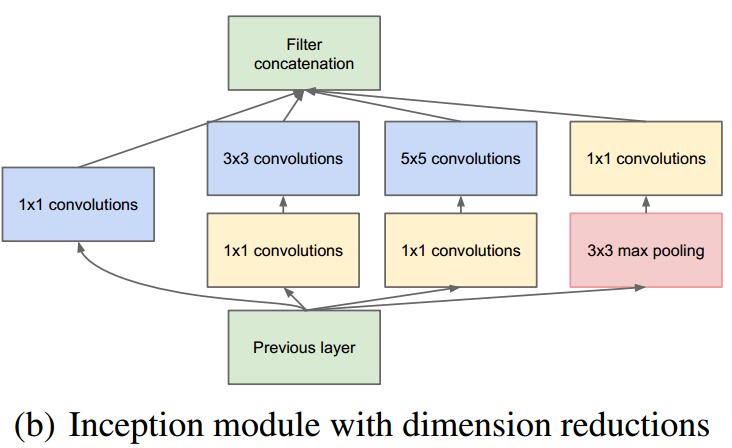
- 采用不同大小的卷积核,意味着得到不同大小的感受野,最后拼接起来意味着不同尺度的融合。
- 之所以卷积核采用1,3,5,主要为了方便对齐。设定步长$stide=1$之后,只要设定相应的$padding$为0, 1, 2,那么卷积之后即可得到相同维度的特征,那么这些特征即可拼接再一起。
- 在一个方向上先采用了最大化池化,这样能得到更好的效果。
- 采用了$1*1$卷积
- 网络越到后面,特征越抽象,而且每个特征涉及的感受野也更大了,因此随着层数的增加,$33$和$55$卷积的比例也要增加。
由多个Inception模块构建成了GoogLeNet
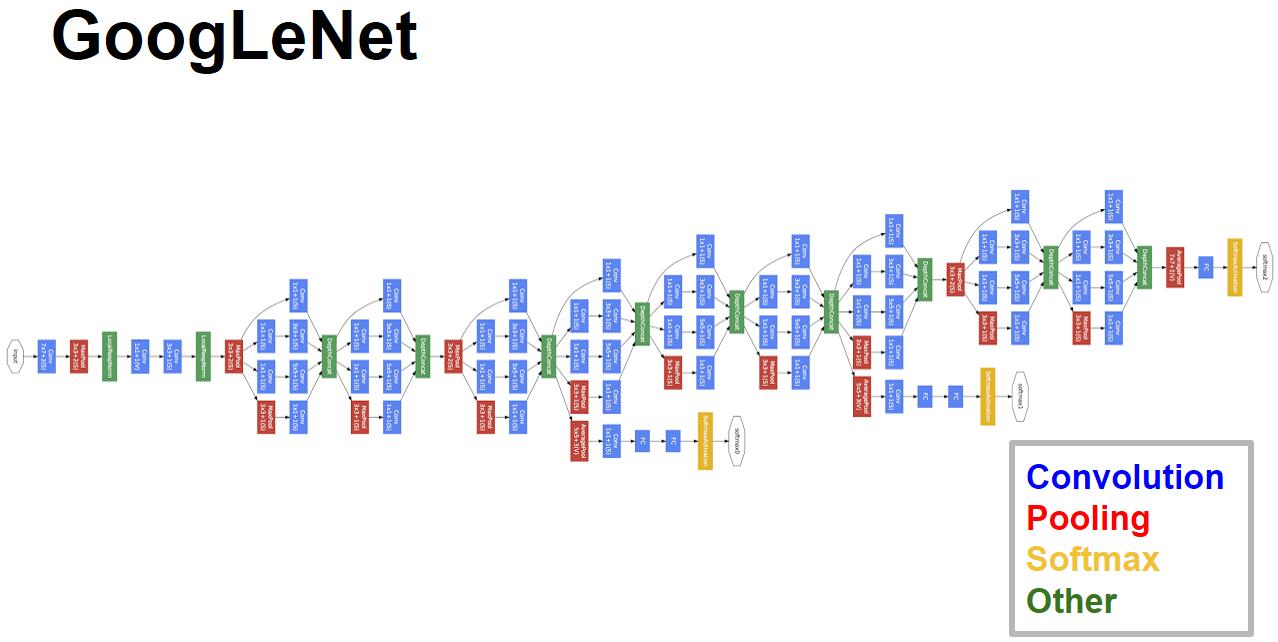
在Inception-v1之后为了提高训练速度和效果出现了许多衍生版本,但思想都不变,理解了Inception模块,就嫩理解Inception网络。
Inception模块的pytorch实现
class Inception_base(nn.Module):
def __init__(self, depth_dim, input_size, config):
super(Inception_base, self).__init__()
self.depth_dim = depth_dim
#mixed 'name'_1x1
self.conv1 = nn.Conv2d(input_size, out_channels=config[0][0], kernel_size=1, stride=1, padding=0)
#mixed 'name'_3x3_bottleneck
self.conv3_1 = nn.Conv2d(input_size, out_channels=config[1][0], kernel_size=1, stride=1, padding=0)
#mixed 'name'_3x3
self.conv3_3 = nn.Conv2d(config[1][0], config[1][1], kernel_size=3, stride=1, padding=1)
# mixed 'name'_5x5_bottleneck
self.conv5_1 = nn.Conv2d(input_size, out_channels=config[2][0], kernel_size=1, stride=1, padding=0)
# mixed 'name'_5x5
self.conv5_5 = nn.Conv2d(config[2][0], config[2][1], kernel_size=5, stride=1, padding=2)
self.max_pool_1 = nn.MaxPool2d(kernel_size=config[3][0], stride=1, padding=1)
#mixed 'name'_pool_reduce
self.conv_max_1 = nn.Conv2d(input_size, out_channels=config[3][1], kernel_size=1, stride=1, padding=0)
self.apply(helpers.modules.layer_init)
def forward(self, input):
output1 = F.relu(self.conv1(input))
output2 = F.relu(self.conv3_1(input))
output2 = F.relu(self.conv3_3(output2))
output3 = F.relu(self.conv5_1(input))
output3 = F.relu(self.conv5_5(output3))
output4 = F.relu(self.conv_max_1(self.max_pool_1(input)))
return torch.cat([output1, output2, output3, output4], dim=self.depth_dim)